
When Zero Trust Meets AI Training: The Zscaler GDPR Data Processing Controversy


TL;DR: Zscaler's CEO boasted about training AI models on "half a trillion daily transactions" from customer logs, triggering GDPR concerns. Despite corporate damage control, fundamental questions remain about data processing transparency, legal bases, and whether cybersecurity vendors can transform from processors to controllers without explicit consent.
The Spark That Lit the Fire
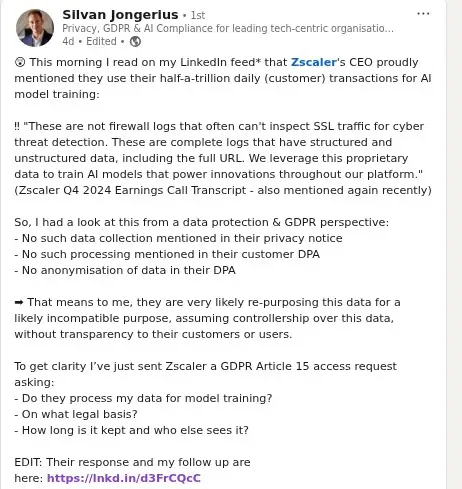
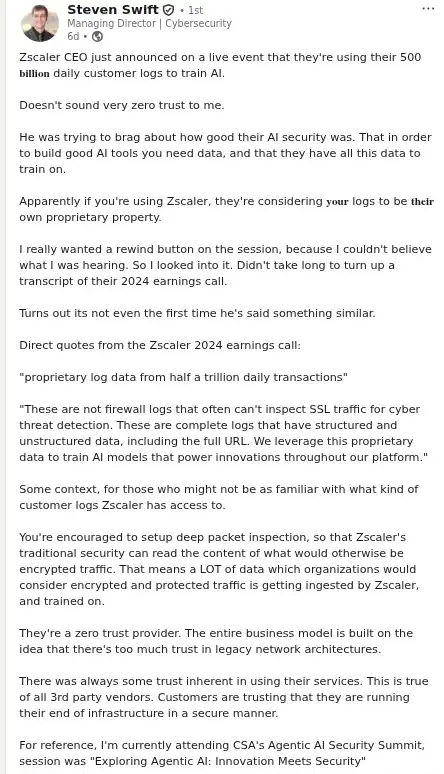
In August 2025, cybersecurity giant Zscaler found itself at the center of a data protection storm. CEO Jay Chaudhry made references this week to "trillions" of Zscaler's transaction-level logs being used to train its AI models. Those remarks were shared online, leading to some consternation regarding the potential impact on the firm's zero-trust promise.
The controversy began when privacy advocates noticed statements from Zscaler's earnings calls where leadership claimed they leverage their massive data pipeline—"over 500 billion transactions per day and hundreds of trillions of signals every day"—for AI model training. For a company whose entire value proposition rests on "Zero Trust" principles, this raised uncomfortable questions about what exactly was being trusted.

The GDPR Challenge
The situation escalated when a privacy-conscious individual filed a formal GDPR Article 15 data subject access request, demanding transparency about how Zscaler processes personal data for AI training purposes. The request, reproduced in the images above, was methodical and legally precise, asking for:
- Categories of personal data processed for AI training
- Legal basis under GDPR Article 6
- Recipients and retention periods
- Automated decision-making information
- Copies of personal data undergoing such processing
The individual's follow-up request cut to the heart of the matter: "For avoidance of doubt, under GDPR Zscaler cannot discharge its obligations by referring me to my employer if Zscaler itself processes data as a controller for AI development or related purposes."

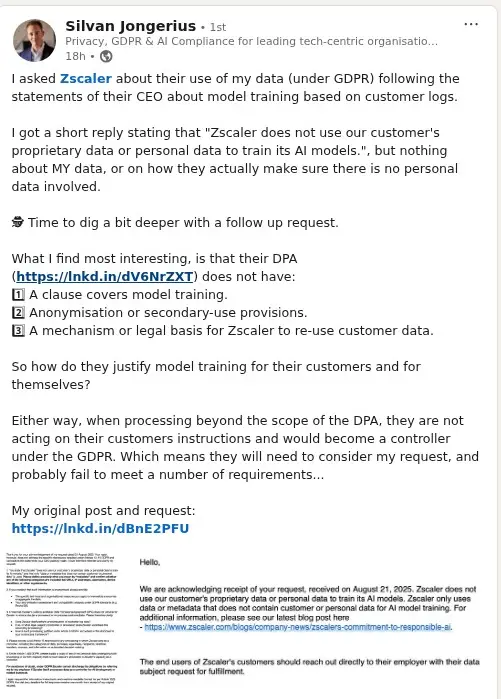
Zscaler's Defensive Response
In a response from Zscaler CISO Sam Curry, the company stressed its commitment to responsible AI. "Zscaler does not use customer data to train its AI models," Curry wrote. "Each customer owns their proprietary information or personal data ... in the Zscaler logs. We only use data or metadata that does not contain customer or personal data for AI model training."
But this response immediately raised more questions than it answered. The company's blog post explained: "Think of it like water flowing through pipes: while the content of the water belongs entirely to each customer, the knowledge of how the water moves—its pressure, velocity, and patterns—can inform the system without ever extracting the water itself."
The metaphor, while poetic, sidesteps crucial technical and legal details about what constitutes "metadata" and whether it truly contains no personal data.
The Technical Reality Gap
Here's where Zscaler's explanations become problematic from a GDPR perspective. Independent reporting interpreted the CEO's remarks as saying Zscaler leverages transactional logs — including structured and unstructured elements and full URLs — as training material for internal AI models.
Full URLs are inherently personal data under GDPR when they can identify or relate to individuals. Consider these examples:
https://linkedin.com/in/john-smith-12345https://company.com/employee-portal?user=jane.doehttps://medical-site.com/patient-dashboard?id=patient123
If Zscaler's AI models are trained on such URLs—even in aggregated form—they're processing personal data. The company's claim that they only use "metadata that does not contain customer or personal data" becomes legally questionable when that metadata includes potentially identifying information.

The Controller vs. Processor Problem
This controversy illuminates a fundamental shift in cloud security relationships. When Zscaler acts as a security service processor for its customers, it operates under strict contractual limitations. But the EDPB's view is that when looking at whether the controller conducted an appropriate assessment, supervisory authorities should consider "whether the controller has assessed some non-exhaustive criteria, such as the source of the data and whether the AI model is the result of an infringement of the GDPR".
The key legal question: If Zscaler repurposes customer log data for its own AI development, does it transform from a processor to a controller for that processing? If so, it needs:
- A separate legal basis under GDPR Article 6
- Transparent privacy notices about AI training
- Data subject rights mechanisms for the AI processing
- Legitimate interest assessments if relying on Article 6(1)(f)
Zscaler's Data Processing Agreement (DPA) reportedly lacks provisions for AI model training, suggesting this processing wasn't contemplated in the original customer agreements.

The Broader Industry Implications
Zscaler isn't unique. Security researchers and frustrated administrators reacted because the phrasing used in earnings calls and media reports — mention of "proprietary logs," "full URLs," and "complete logs" — reads to many like an admission of training on high-fidelity customer records.
This reflects a broader trend where cybersecurity vendors are pivoting to AI-powered services, often leveraging the massive data flows they already process. The regulatory landscape is struggling to keep pace:
- The EDPB has also emphasised that safeguards can assist in meeting the balancing test for legitimate interest processing
- The CNIL affirms that training AI models on personal data sourced from public content can be lawful under the GDPR's legitimate interest basis, provided certain conditions are met
- The EDPB Opinion also emphasised the need for controllers deploying the models to carry out an appropriate assessment on whether the model was developed lawfully
The Transparency Deficit
What makes this case particularly concerning is the apparent lack of proactive transparency. Customers and data subjects weren't informed about AI training uses until after public controversy erupted. Article 13 GDPR requires that data subjects be informed of their rights, including the right to object (which applies where processing is based on legitimate interests). In some cases, to satisfy the fairness principle, it may be appropriate to provide a specific notification to data subjects and give them the opportunity to object before processing is carried out.
What This Means for Organizations
For companies using Zscaler and similar services:
Immediate Actions:
- Review your vendor contracts for AI training clauses
- Understand whether vendors are processing your data as controllers for AI purposes
- Assess your own GDPR obligations for vendor data processing
Strategic Considerations:
- Explicit model-training clauses: Prohibit any use of customer-identifiable data for third-party model training unless explicitly consented to in writing
- Implement vendor auditing procedures for AI development activities
- Consider data residency and sovereignty implications

The Road Ahead
While the CNIL's guidance provides welcome clarity on how legitimate interest can support GDPR compliance during AI training, it does not attempt to resolve adjacent legal or strategic questions. The Zscaler controversy highlights the urgent need for:
- Clearer regulatory guidance on processor-to-controller transitions in AI contexts
- Industry standards for transparency in AI training by service providers
- Better contractual frameworks that anticipate AI development uses
- Technical solutions for privacy-preserving AI training
Conclusion
The Zscaler case represents more than a single company's misstep—it's a preview of the regulatory challenges facing the entire cybersecurity industry as AI becomes central to service delivery. Zero trust underpins the Zscaler USP, with the Z in its company name standing for zero. But when it comes to AI training transparency, the industry may need to rebuild that trust from the ground up.

The controversy also demonstrates the power of individual GDPR rights. A single, well-crafted data subject access request exposed gaps that could affect millions of users worldwide. As AI deployment accelerates, such scrutiny will likely intensify.
Organizations should prepare now: audit your vendor relationships, understand the data flows, and ensure your AI-powered security tools don't become compliance liabilities. In the age of AI-driven cybersecurity, trust must be not just zero—it must be earned through transparency, legal compliance, and respect for fundamental privacy rights.
This analysis is based on publicly available information and should not be considered legal advice. Organizations should consult qualified data protection counsel for specific compliance guidance.



